Amazon SageMaker Canvas を使ってノーコードで AI による予測をする
はじめに
こちらは APN Ambassadors(AWS Ambassadors)によるアドベントカレンダー「Japan APN Ambassador Advent Calendar 2021」での20日目の記事となります。 AWS Ambassadors の詳細については、下記の記事をご覧ください。
本記事では AWS re:Invent 2021 にて発表された「Amazon SageMaker Canvas」(以下、SageMaker Canvas)の簡単な動作検証を実施してみたいと思います。
SageMaker Canvas
概要
SageMaker Canvas は AWS re:Invent 2021 で発表された新機能であり、ノーコードで AI を用いた予測が行えます。 手元に構造化されたデータがあれば、30 分程度で簡単な予測結果が得られます。

ビジネスおよびテクニカル観点で SageMaker Canvas を見てみます。
ビジネス観点
- ビジネスアナリストやプロダクトオーナーがデータサイエンティストやエンジニアの手を借りずに自身の手でデータを検証できる
- 「依頼」には余計なオーバーヘッドがかかりがち…
- 手元にあるデータでサクッと仮説検証して、結果をデータサイエンティストやエンジニアに共有できればビジネスへの導入も円滑に進みやすい
- スポンサーに有用性を説明して出資なども取り付けやすい
- 下記のようなビジネス課題に対するソリューションになる(開発者ガイドより引用)
- Reducing employee churn(従業員の離職を減らす)
- Detecting fraud(不正を検出する)
- Forecasting sales(売上を予測する)
- Optimizing inventory(在庫量を予測して最適化する)
テクニカル観点
- SageMaker Canvas の仕様や挙動から背後で SageMaker Autopilot が使われていると思われるため、SageMaker Autopilot でできることは実現可能
- 学習データの分析(統計情報や欠損値の割合の分析など)
- 下記の学習アルゴリズムを用いたモデル構築
- 回帰
- 分類(二値・多値)
- 時系列予測
- 構築したモデルによる推論
- モデルの判断根拠の可視化(説明可能な AI: XAI)
使い方
SageMaker Canvas の概要や有用性がわかったところで、具体的な使い方を見ていきたいと思います。 SageMaker の開発者ガイドより、SageMaker Canvas は事前準備を含めて、下記の 6 ステップで予測まで実行することができます。
- Step 0: 事前準備
- Step 1: SageMaker Canvas へのログイン
- Step 2: データのインポート
- Step 3: モデルの構築
- Step 4: モデルの評価
- Step 5: 予測
ここからは SageMaker Canvas を使って簡単な動作検証を実施してみたいと思います。
今回は UCI Machine Learning Repository の Bank Marketing のオープンデータを利用して、二値判別問題に取り組みます。 このデータにはポルトガル銀行の顧客の属性情報(年齢、職業、住宅ローンの有無など)とその顧客が定期預金を申し込んだかどうかの情報が含まれています。 属性情報から何らかの法則性を見出せれば、定期預金を申し込んでくれそうな顧客に対して効率的に営業活動ができます。
Step 0: 事前準備
このステップでは、下記を実施します。
- Step 0-1: AWS リソースに対する適切な権限を持った IAM ユーザにログインする
- Step 0-2: S3 に学習データとテストデータをアップロードする
- Step 0-3: SageMaker Domain をセットアップする
Step 0-1: AWS リソースに対する適切な権限を持った IAM ユーザにログインする
AWS マネジメントコンソールから IAM ユーザにログインします。
今回は簡単な動作検証なので AdministratorAccess 権限を持つ IAM ユーザで実施しますが、特にビジネスで利用する際は AWS のベストプラクティスにしたがって必要最小限の権限に制約してください。
SageMaker Canvas は、本稿の執筆時点では下記のリージョンでのみ利用が可能であり、東京&大阪リージョンに対応していません。 今回は「米国西部(オレゴン)」を利用します。
Step 0-2: S3 に学習データとテストデータをアップロードする
S3 のコンソール画面に移動し、学習データとテストデータをアップロードします。

SageMaker Canvas にファイルに対して下記の制約がありますので、注意してください。
- ファイルサイズは 5GB 以下で、CSV 形式とする
- 欠損値補完などの前処理を事前に実施する(前処理機能が実装されていない)
Step 0-3: SageMaker Domain をセットアップする
この手順は SageMaker Domain が未セットアップの場合にのみ必要となります。
SageMaker のコンソール画面に移動し、「Canvas」を選択します。

SageMaker Domain が未セットアップの場合は、下図に示すセットアップ画面に誘導されます。 構成状況が不明の場合でもこの方法で確認できます。
今回は「高速セットアップ」で進めます。

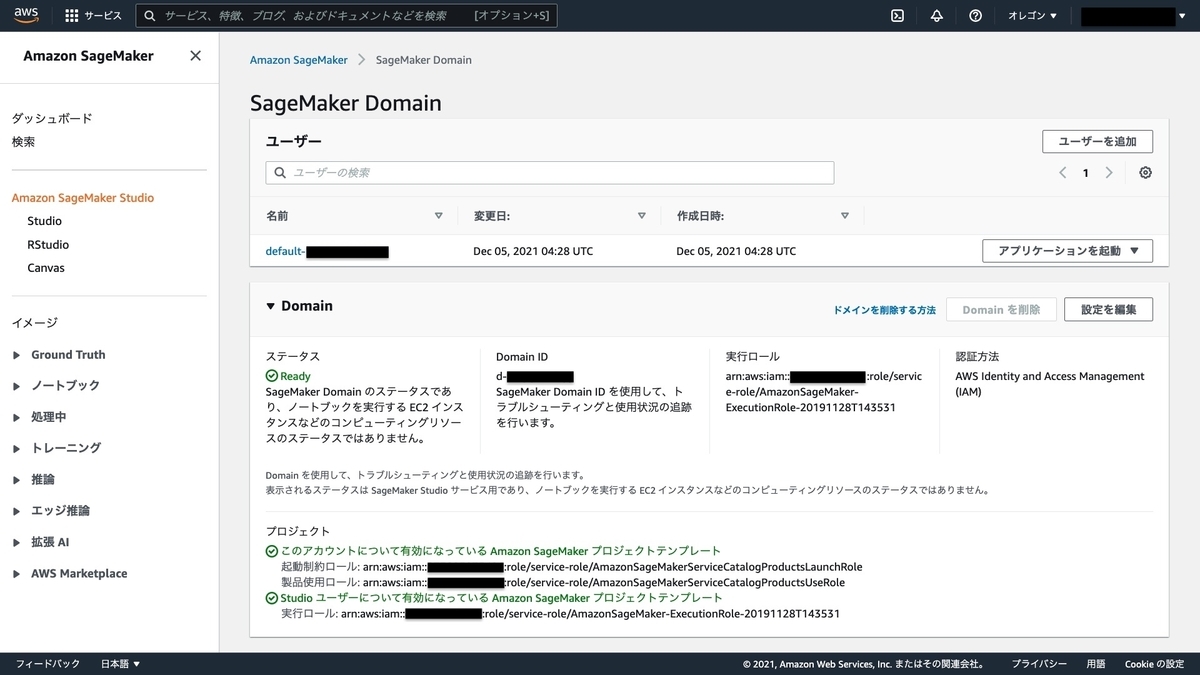
SageMaker Domain は下記のリソースで構成され、AWS アカウントの 1 つのリージョンあたりに 1 つだけ構成できます。
- EFS ボリューム
- 認証されたユーザの一覧
- 様々なセキュリティ、アプリケーション、ポリシー、VPC の構成
SageMaker Domain は SageMaker Studio でも活用されています。 例えば、同じ SageMaker Domain に所属するユーザ間では EFS ボリュームを介してノートブックなどのファイルを共有できます。
下記のような画面となれば SageMaker Domain の構成完了です。
Step 1: SageMaker Canvas へのログイン
このステップでは、下記を実施します。
- Step 1-1: SageMaker Canvas を起動する
Step 1-1: SageMaker Canvas を起動する
SageMaker Canvas は赤い矢印で示した「アプリケーションを起動」のプルダウンから「Canvas」を選択すると起動できます。

起動に成功すると、下図のような画面が表示されます。

初回接続時にチュートリアルが表示されますが、左下の「?」を選択すればいつでも確認できます。

Step 2: データのインポート
このステップでは、下記を実施します。
- Step 2-1: S3 から学習データとテストデータをインポートする
ここでは、機械学習モデルの構築で利用する学習データと予測で利用するテストデータをインポートします。
Step 2-1: S3 から学習データとテストデータをインポートする
左側のメニューを開くと、それぞれのアイコンの内容が確認できます。 「Datasets」を選択します。
画面右上もしくは中央下の「Import」を選択します。
データが格納されている S3 Bucket を選択します。
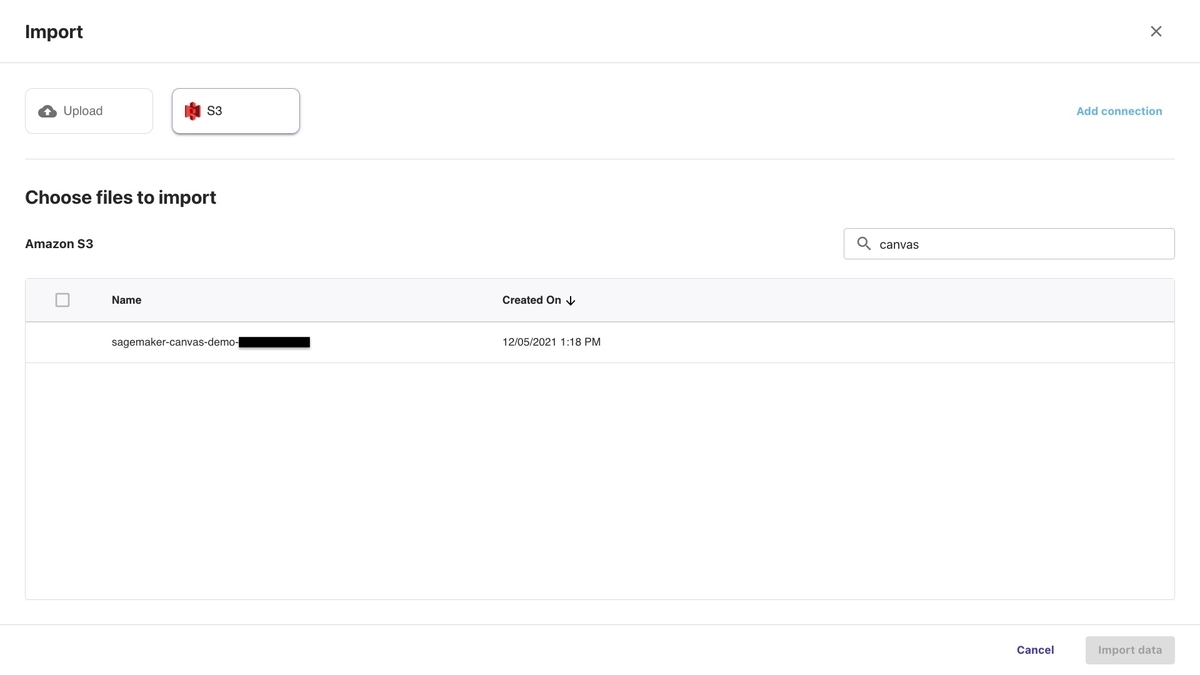
インポートするデータにチェックをつけて、「Import data」を選択します。

ファイル名をクリックすると、データの内容を確認できます。
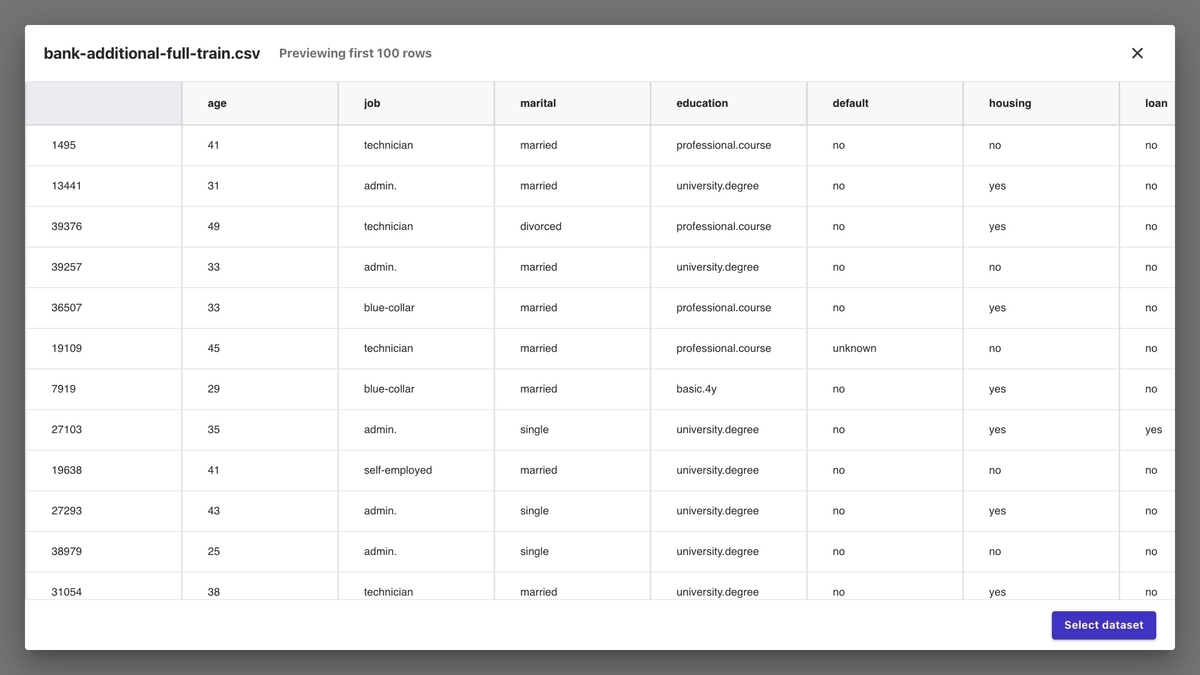
下図のように「Status」が「Ready」となれば完了です。
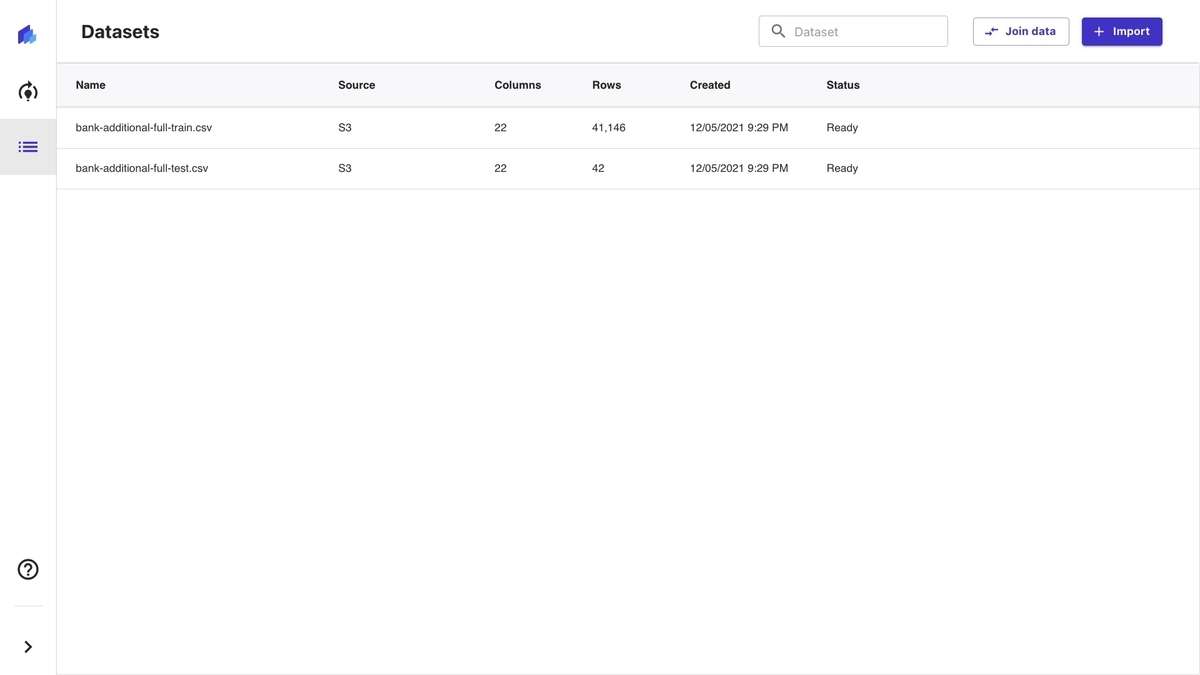
なお、開発者ガイドによるとデータソースとして下記がサポートされると記載されますが、本稿の執筆時点では S3 のみが利用可能です。 上図では「Upload」というボタンがあり、ローカル PC からのアップデートができそうに見えますが、ボタンが活性化されておらず利用できません。
- ローカル PC
- S3
- Redshift
- Snowflake
また、今回は実施しませんが、「Join data」を選択するとインポートしたデータを結合できます(図は SageMaker の開発者ガイド より引用)。

Step 3: モデルの構築
このステップでは、下記を実施します。
- Step 3-1: 「Models」に移動する
- Step 3-2: 機械学習モデルの名前を設定する
- Step 3-3: 学習データを選択する
- Step 3-4: 予測対象となるカラム名を選択する
- Step 3-5: 学習方法を選択して実行する
Step 3-1: 「Models」に移動する
左側のメニューで「Models」を選択後、画面右上もしくは中央下の「New model」を選択します。
Step 3-2: 機械学習モデルの名前を設定する
機械学習モデルの名前を入力して、「Create」を選択します。

Step 3-3: 学習データを選択する
学習データとするデータを選択して、「Select data」を選択します。

Step 3-4: 予測対象となるカラム名を選択する
「Target column」から予測対象となるカラム名を選択します。 今回は定期預金を申し込んだかどうかが記録されている「y」を選択します。
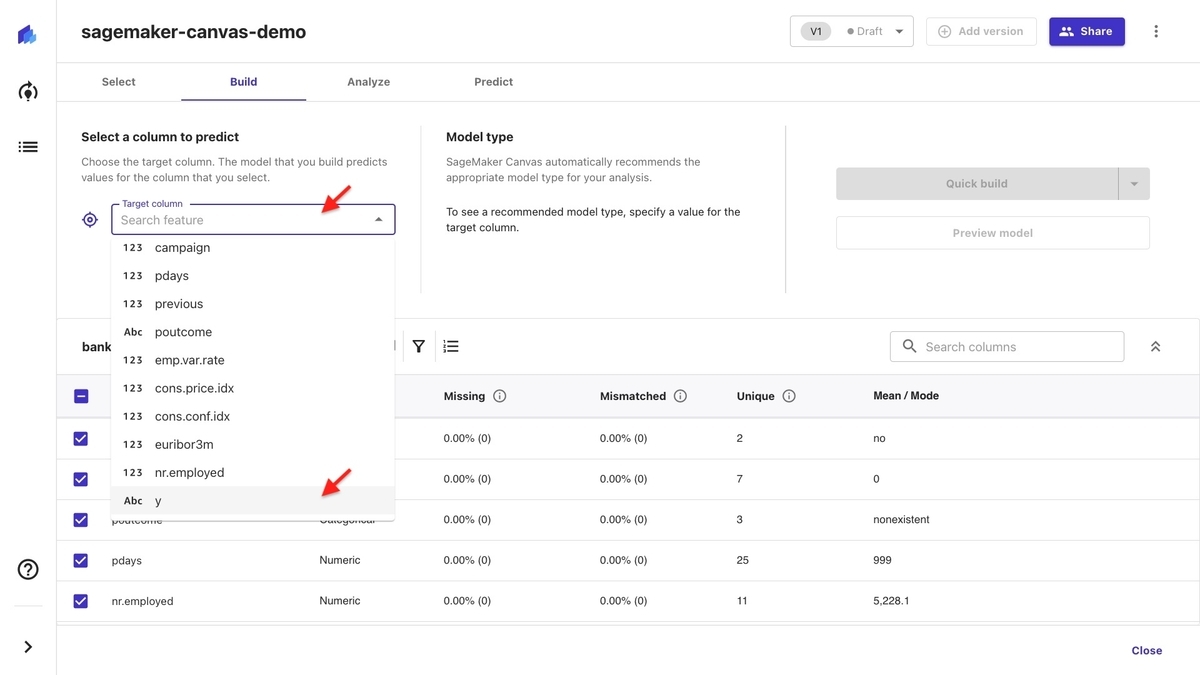
赤枠部分に学習データの「y」の比率が示されています。 この学習データは「no(定期預金を申し込まない)」よりも「yes(定期預金を申し込む)」が著しく少ない不均衡データであることがわかります。
青枠部分には「y」のデータの内容から、SageMaker Canvas が 自動で「2 category prediction(二値判別予測)」と判断し、その結果が示されています。 判断が間違っている場合は、その下の「Change type」で変更できます。
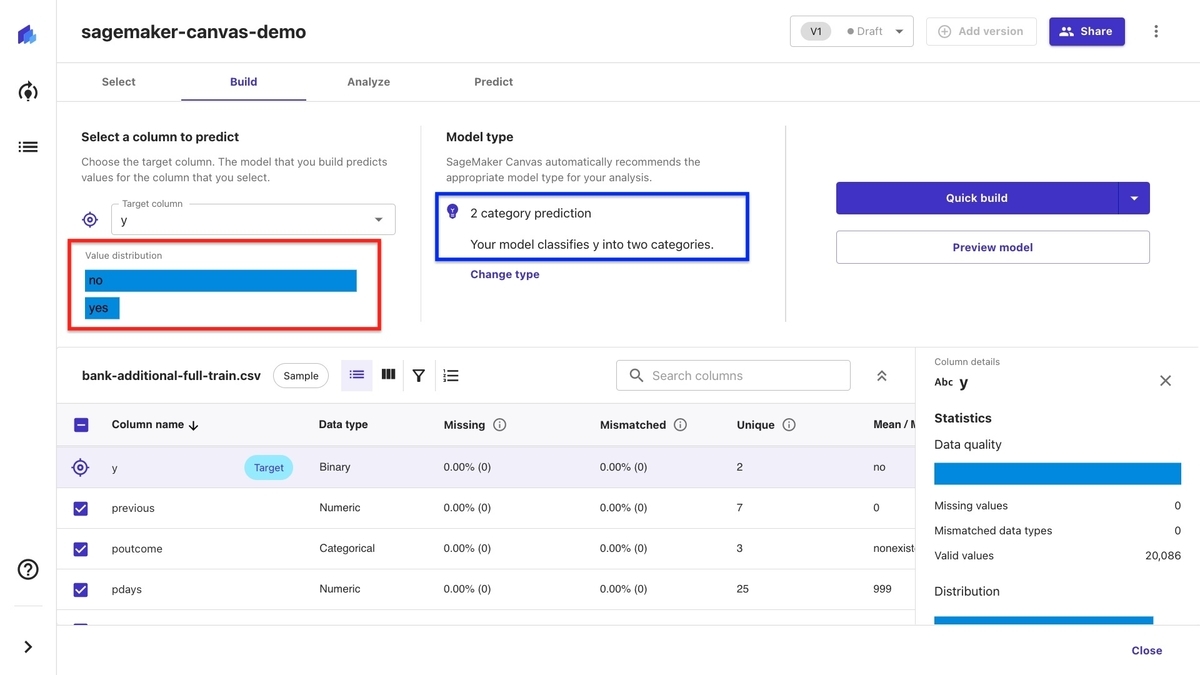
画面の下半分には学習データのカラム別の分析結果が示されています。 データ型や欠損割合に加えて、平均や中央値などの統計情報も提示されます。
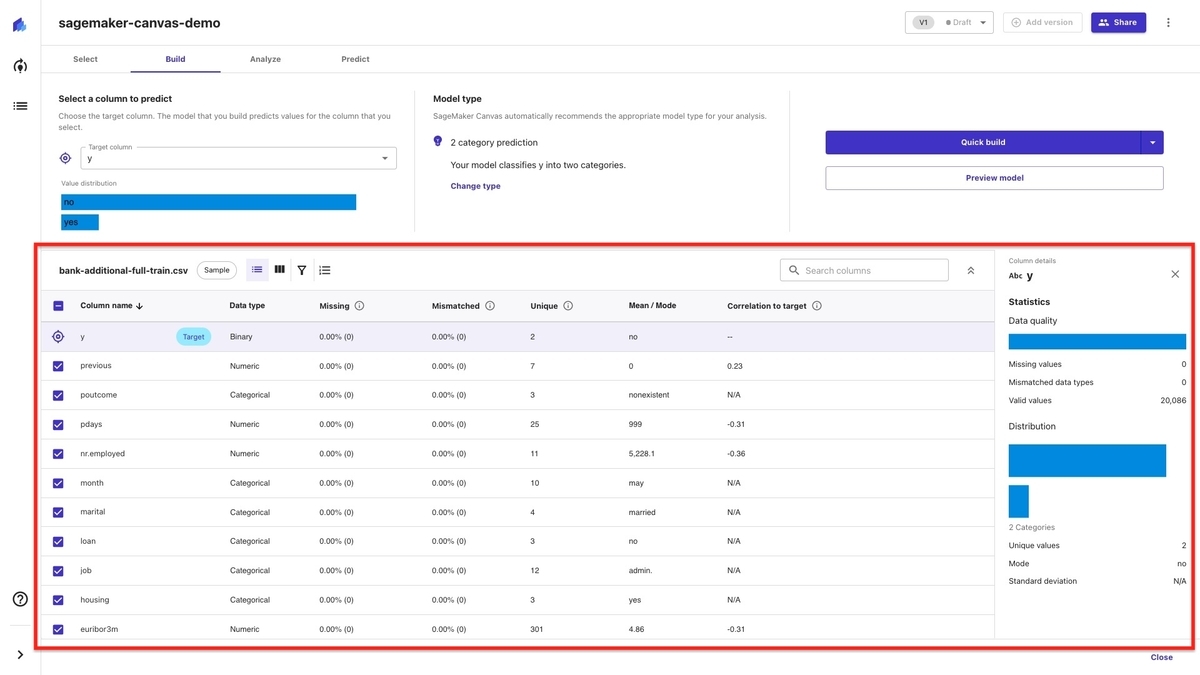
分析結果の上部にあるアイコンを選択すると、データの分析観点を変更したり、フィルタなどもできます。 下図は矢印を選択したものです。 カラム別にデータの分布が可視化され、学習データの中の 100 行が示されています。

Step 3-5: 学習方法を選択して実行する
矢印のプルダウンを選択すると、2 つの学習方法を選択することができます。 今回は「Quick build」を選択します。
- Standard build: 数時間かけて 250 モデルを作成し、精度が最良のものを選択する
- Quick build: 数分でクイックに精度を提示する(恐らく 1 モデルのみの構築)
今回は「Quick build」を選択するので数分で結果が得られますが、「Standard build」は結果を得るまでに数時間かかります。 事前に精度の見通しを持てるため、非常にありがたい機能です。
なお、画面上部の「Share」を使うと学習モデルを他者に共有できますが、「Quick build」では共有ができない点に注意してください。

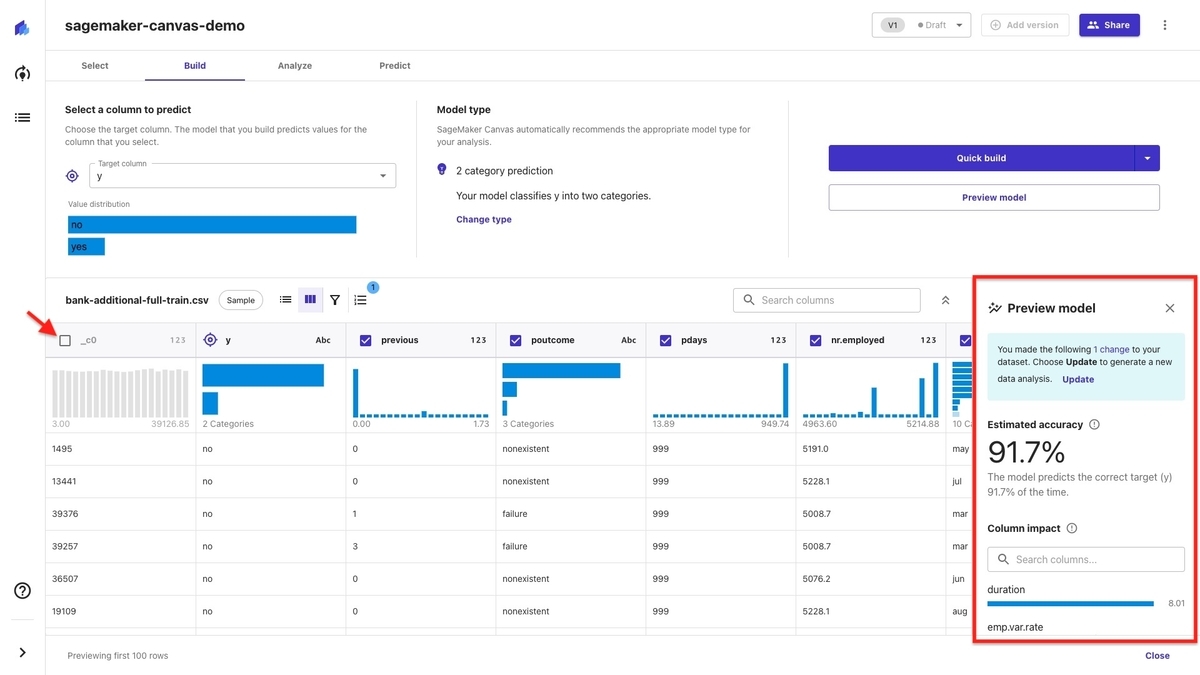
「Preview model」を選択して数分待つと、画面右下に「Estimated accuracy(モデルの予測精度)」と「Column impact(カラムの値が予測に与える影響度合い)」が表示されます。
「Preview model」の実体は「Quick build」と考えられますが、この時に構築したモデルは偶然良いもしくは悪い精度を出す可能性があるため、結果の妥当性を求めたい場合は「Standard build」を選択すると良いでしょう。

「_c0」というカラムは学習データの行番号を示すものであり、学習には不要なデータでした。 そのような場合はカラム名の左横のチェックを外すと学習から除外でき、数分待つと予測精度も更新できます。
学習データに問題ないことが確認できたら「Quick build」を選択します。 下図のような画面に遷移するので、学習が完了するまで数分待ちます。

Step 4: モデルの評価
このステップでは、下記を実施します。
- Step 4-1: モデルを評価する
ここでは、モデルの評価を行います。 正解がわかっている学習データを用いた評価となります。
Step 4-1: モデルを評価する
学習が完了すると、下図のような画面が表示されます。 「精度」と「カラムの値が予測に与える影響度合い」が図で示されます。
今回は「duration(最後の連絡期間)」が最上位になりました。 なお、今回利用した UCI のデータセットの説明では「duration」が「y」に大きな影響を与えるので検証以外で利用する場合には注意せよとの記載があります。 データの性質と一致する結果となりました。

「Scoring」を選択すると、予測の正解と不正解の割合が図示されます。
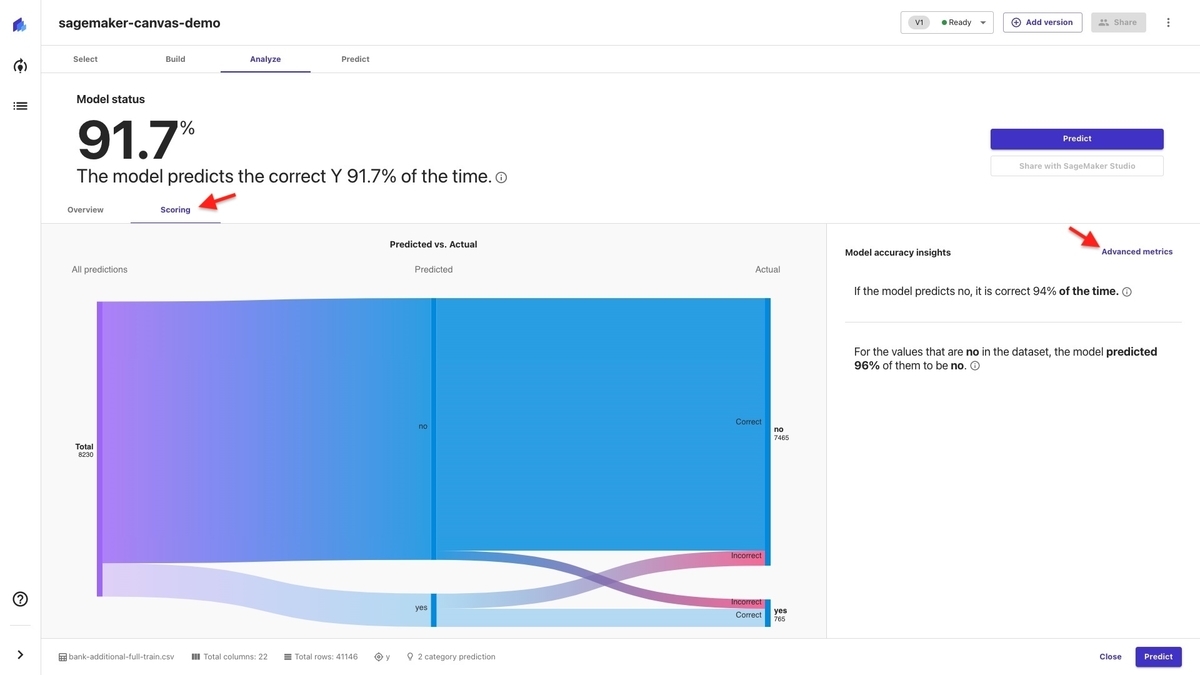
画面の右の方にある「Advanced metrics」を選択すると、「no(定期預金を申し込まない)」と「yes(定期預金を申し込む)」のそれぞれについて、詳細なメトリクス(指標値)を確認することができます。 「Download」を選択すると、画像として保存もできます。
- F1(適合率と再現率の調和平均)
- Accuracy(精度、正解率)
- Precision(適合率)
- Recall(再現率)
- AUC(ROC 曲線の面積)
- 混同行列の内訳


「yes」はデータ量の不足もあって十分な指標値が得られていません。 「no」はそこそこですが、誤検出や検出漏れが少なくないためビジネスで利用するには十分とは言えません。 このような結果を得た場合は「yes」「no」ともデータ量を増やし、かつ、両者の比率も揃える必要があるでしょう。
Step 5: 予測
このステップでは、下記を実施します。
- Step 5-1: 「Predict」を選択する
- Step 5-2: 「Batch prediction」を選択する
- Step 5-3: テストデータを使って予測する
- Step 5-4: 予測結果を確認する
Step 4 で構築したモデルを使って、未知データ(定期預金を申し込むかどうかわからない顧客のデータ)から予測を取得します。
Step 5-1: 「Predict」を選択する
確認が完了したら、右上もしくは右下の「Predict」を選択します。

Step 5-2: 「Batch prediction」を選択する
SageMaker Canvas は下記の 2 つの予測方法にて予測を行えます。
- Batch prediction: 予測対象のデータをファイルで一括指定する
- Single prediction: 予測対象のカラムの値を手動で設定する
「Batch prediction」を選択して、「Select dataset」を選択します。
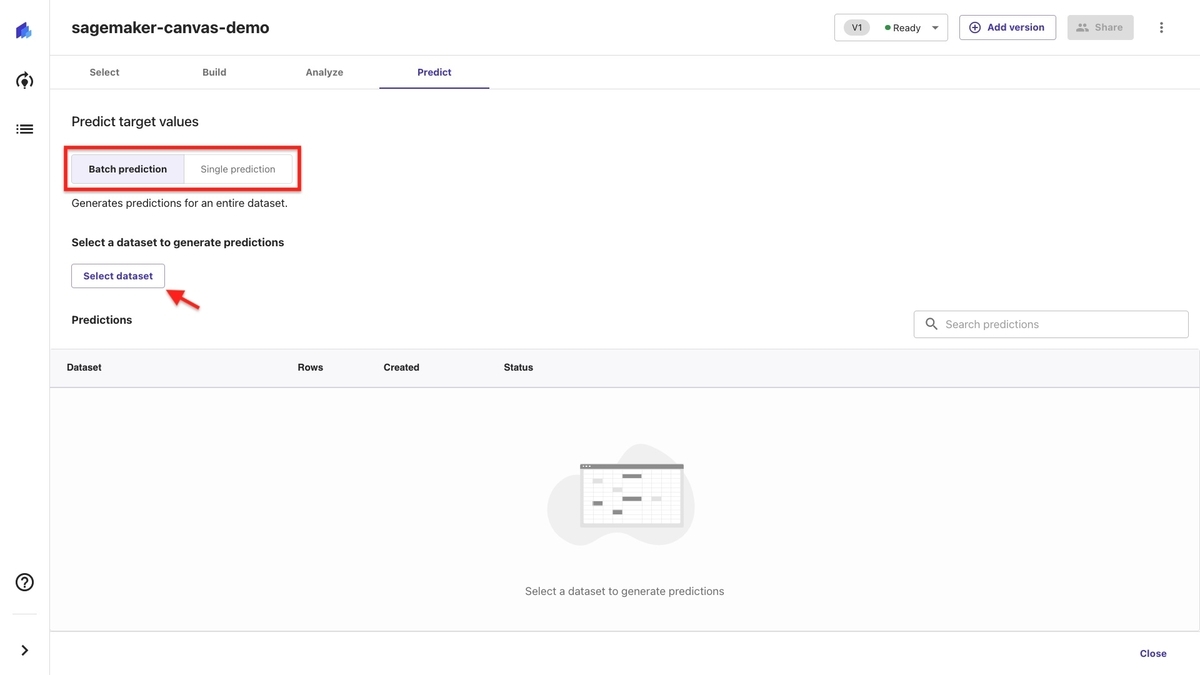
Step 5-3: テストデータを使って予測する
テストデータを選択して、「Generate prediction」を選択します。

Step 5-4: 予測結果を確認する
少々分かりづらいですが、予測が完了すると画面の下部に黒いポップアップが表示されます。 「View」を選択すると、下図のように表形式で予測結果が提示されます。
- Prediction (y): 予測した「y(定期預金を申し込むかどうか)」の値
- Probability: 予測した「y」の値をとる確率
「Download CSV」を選択すると、予測結果を CSV 形式のファイルとして保存できます。

なお、「Single prediction」を選択すると、各カラムの値を手動で変更して、その時の予測結果がどのように変化するかを確認できます。 業務知識をもとに値を設定して予測結果を得るなどのシミュレーションができます。

制約事項
動作検証の中でも触れましたが、SageMaker Canvas の主な制約事項をまとめます。
- 東京&大阪リージョンでは利用不可
- S3 からのデータ(5GB 以下& CSV 形式)のインポートのみに対応
- 回帰、分類(二値・多値)、時系列予測にのみ対応
- 「Quick build」はモデルの共有不可
SageMaker Canvas はまだ発表されたばかりですので、順次機能が拡張されていくものと考えられます。
まとめ
本稿では SageMaker Canvas について、開発者ガイドのチュートリアルを利用しながら簡単な動作検証を実施しました。 製品の謳い文句の通りにノーコードで AI を利用した予測ができました。
本稿のボリュームはそれなりにありますが、慣れれば Quick build なら 30 分程度で予測結果を得られると思います。 非常に有用なサービスですので、早々の東京&大阪リージョンへの対応を期待したいところです。
Advent Calendar も佳境ですが、AWS Ambassadors の仲間が興味深い記事をたくさん投稿していますので、是非お読みいただければと思います。
参考文献
- Amazon SageMaker Canvas
- Introducing Amazon SageMaker Canvas - a visual, no-code interface to build accurate machine learning models
- Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capability for Business Analysts
- AWS re:Invent 2021 - A deeper look at SageMaker Canvas
- Amazon SageMaker Developer Guide